
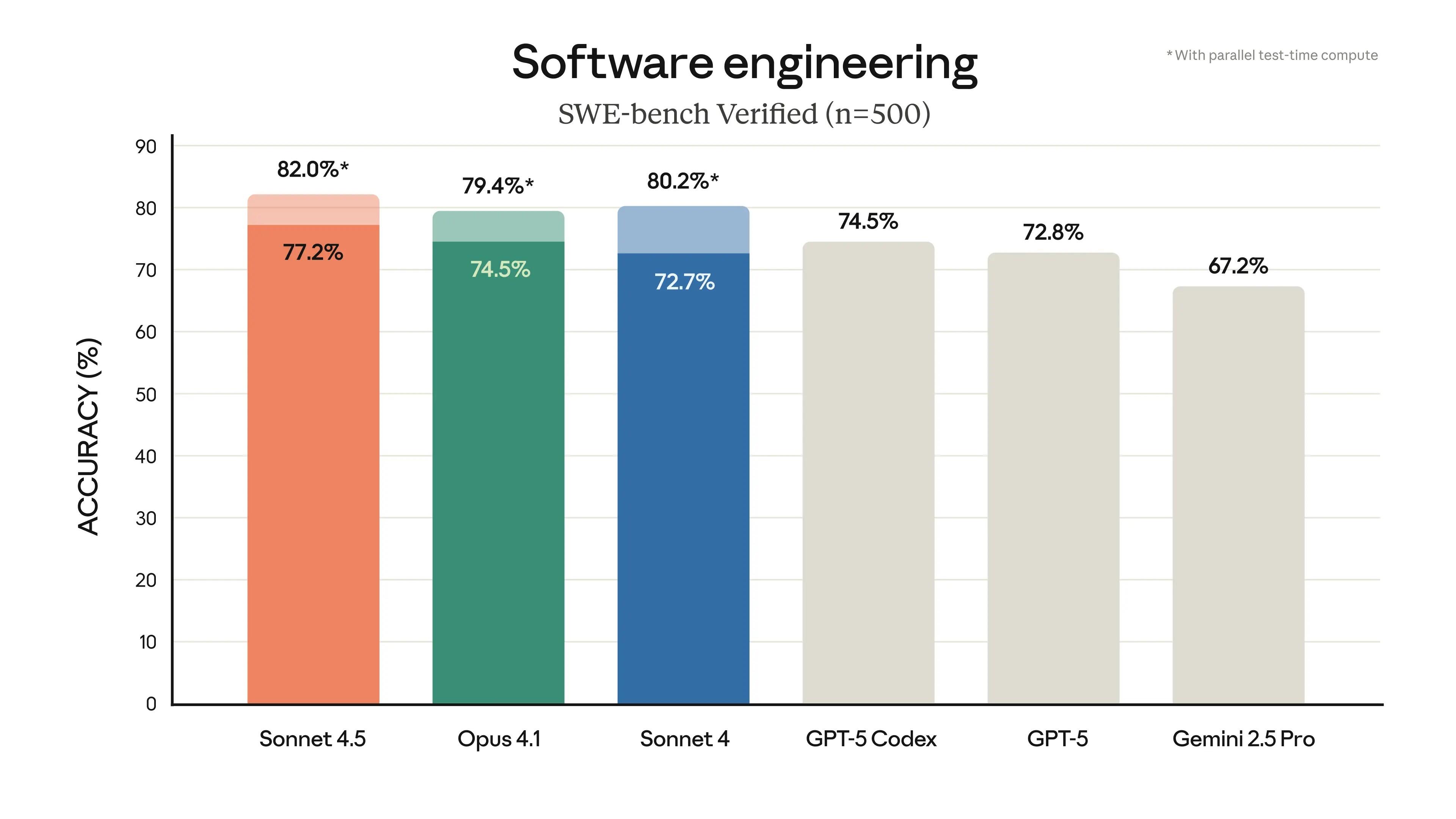
Anthropic's Claude Sonnet 4.5 artificial intelligence (AI) tool has scored 77.2% on SWE-bench Verified, the benchmark that measures how well AI handles real-world software engineering work, putting it ahead of OpenAI's GPT-5 and Google's Gemini 2.5 Pro.
The newly-released model represents a jump from 42.2% to 61.4% on OSWorld testing in just four months, a whopping 45% improvement.
The AI developer says pricing remains unchanged at US$3 per million input tokens and $15 per million output tokens - delivering vastly better output for the same cost.
Microsoft slotted Claude into Copilot 365 last week, and OpenAI has conceded Anthropic's got the edge on work-focused AI applications.
Coding improvements
Anthropic claims Sonnet 4.5 is their most aligned frontier system yet, claiming to have reduced concerning behaviours including sycophancy, deception, and power-seeking tendencies.
“We’ve also made considerable progress on defending against prompt injection attacks, one of the most serious risks for users of these capabilities,” Anthropic said in a statement.
Company engineers have watched Sonnet 4.5 churn through code for 30-plus hours without losing focus on complex, multi-layered projects, versus Opus 4's seven-hour limit earlier this year.
During test runs with enterprise clients, this thing spun up full applications, configured databases, bought domain names, and ran security audits without human oversight.
For investors eyeing AI infrastructure plays, autonomous operation that lasts translates to fewer engineers babysitting systems and lower operational expenditure (opex).
Anthropic's chief product officer has gone on record saying Sonnet 4.5 works for basically every use case.
OSWorld results jumped from 42.2% to 61.4% in four months, with parallel test-time compute pushing SWE-bench Verified results to 82.0%.
Sonnet 4.5 outperforms GPT-5 and Gemini 2.5 Pro across virtually every coding evaluation, though Google and OpenAI maintain an edge in visual reasoning, a smaller chunk of business applications.
Michael Truell, CEO of Cursor - one of the hottest tools in the developer ecosystem - called Sonnet 4.5 “state-of-the-art”, particularly for those sprawling, multi-day programming projects that used to require a team.
Finance, legal, medical, and STEM specialists testing Sonnet 4.5 reported dramatically sharper domain knowledge and reasoning against earlier versions, including the pricier Opus 4.1 - with financial services firms getting investment-grade analysis for complex risk models and portfolio work requiring materially less human checking.
False positive rates on safety classifiers have dropped tenfold, meaning fewer times the system incorrectly flags legitimate work and less frustrated staff dealing with blocked requests.
Can Anthropic hold this lead?
Anthropic's already a US$183 billion behemoth, with Amazon's backing and revenue flowing through API access to coding platforms like Cursor, Windsurf, and Replit, while Apple and Meta reportedly run Claude internally.
OpenAI's GPT-5 costs roughly two-thirds less per token than Claude Sonnet 4, but that advantage shrinks when factoring in accuracy gains that reduce token consumption through fewer iterations.
Hai's security agents slashed vulnerability processing time by 44% and lifted accuracy 25%, whilst Devin saw planning capabilities jump 18% and end-to-end task completion rise 12% - efficiency gains that flow through to quarterly results.
The four-month sprint from Sonnet 4 to Sonnet 4.5 demonstrates rapid iteration speed, with the company also releasing the Claude Agent SDK to hand programmers the same infrastructure powering Claude Code, building an ecosystem that raises switching costs.
Google's Gemini 3 is landing soon to test Anthropic's new coding crown, with rapid improvement cycles across all major players suggesting leadership positions flip faster than they used to, rewarding companies with distribution muscle, deep client relationships, and pricing power.


